 |
Un computer č una macchina costituita da un insieme di componenti elettroniche: č facile immaginare quindi, come tutto il funzionamento della macchina dipenda da un flusso continuo di segnali elettrici, sincronizzati da un clock, che codificano, in notazione binaria, le informazioni immagazzinate ed elaborate all'interno della macchina stessa.
Per quanto possa essere complessa e sofisticata l'architettura di un elaboratore elettronico, questo potrebbe sembrare non molto dissimile da un qualsiasi altro elettrodomestico presente nella nostra casa. Tuttavia esiste una differenza sostanziale tra un computer ed una lavatrice: per quanto moderna e dotata di sofisticati meccanismi elettronici, una lavatrice potrŕ sempre e solo lavare dei panni, mentre il computer puň essere istruito per svolgere compiti anche molto differenti tra di loro.
Come si istruisce un computer? Mediante un programma, ossia tramite una sequenza ben definita di istruzioni che la macchina č in grado di tradurre in funzioni elementari facilmente eseguibili. Schematicamente possiamo dire che le caratteristiche principali di un calcolatore sono:
Come rovescio della medaglia di queste caratteristiche 'positive', possiamo individuare alcune caratteristiche 'negative' di cui č bene tenere conto:
Riassumendo, possiamo dire che il calcolatore č un esecutore di ordini impartiti dall'utente-programmatore, assai preciso ed efficiente, ma un po' stupido, si limita cioč ad eseguire ciň che gli viene chiesto, a prescindere dalla correttezza di quanto gli viene ordinato di compiere ai fini della soluzione del problema (in un certo senso si puň dire che č un po' cieco).
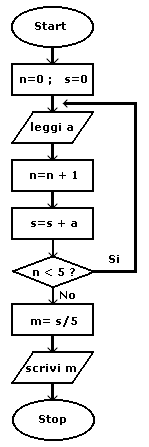
Per capire meglio quanto č stato detto vediamo un esempio elementare di programma per un calcolatore elettronico. Supponiamo che il problema da risolvere sia quello di effettuare la media aritmetica tra 5 numeri forniti dall'utente. Il calcolatore deve leggere in input i cinque numeri, sommarli, memorizzando la somma da qualche parte nella sua memoria ed infine dividere per cinque la somma totale e stampare il risultato. Una codifica di questo algoritmo risolutore potrebbe essere la seguente:
Eseguendo in sequenza le istruzioni del programma (che sono evidentemente molto elementari), il calcolatore č in grado di risolvere il problema che noi ci eravamo posti. Naturalmente l'algoritmo č espresso in lingua italiana: per essere capito dal computer sarebbe stato necessario tradurlo in linguaggio macchina (un linguaggio assai ostico ed innaturale, basato essenzialmente sulla codifica binaria su cui il computer č in grado di operare). Il linguaggio macchina ed il nostro linguaggio naturale sono estremamente distanti fra di loro: quest'ultimo pieno di ambigue sfumature, estremamente coinciso e criptico il primo; per raggiungere un buon compromesso tra le due parti che si devono comprendere (noi e la macchina) sono stati progettati numerosi linguaggi di programmazione ad alto livello, ovvero un insieme di parole chiave e di regole sintattiche, non troppo distanti dal nostro linguaggio naturale, ma facilmente traducibili (in modo automatico, mediante un programma chiamato compilatore) in istruzioni di linguaggio macchina.
Ogni programma per un calcolatore elettronico, utilizza la logica ed i concetti espressi (in estrema sintesi) nei paragrafi precedenti. Č bene saperlo, anche se magari non ci si troverŕ mai a dover scrivere un programma, perché questo puň aiutarci a capire che quasi sempre, quando il calcolatore non esegue ciň che noi vorremmo, a meno di guasti hardware non č lui che sbaglia, ma siamo noi ad aver fornito delle istruzioni incomplete o fuorvianti che non lo portano a raggiungere la soluzione cercata.
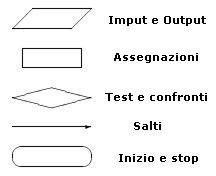
Č spesso utile aiutarsi nella progettazione di un algoritmo, mediante la stesura di appositi diagrammi di flusso che, con una simbologia standard, ci permettono di rappresentare graficamente il flusso seguito dall'elaboratore durante l'esecuzione del nostro programma.
In generale, le operazioni fondamentali che č possibile compiere mediante un programma deterministico sono cinque:
Nella rappresentazione di un algoritmo mediante un diagramma di flusso si usa un simbolo diverso per ognuna di queste operazioni:
|
L'esempio riportato nella pagina precedente potrebbe quindi essere rappresentato con il diagramma di flusso rappresentato in figura 2.
 |
Per rendere piů chiari e leggibili i programmi č opportuno rifarsi alle regole della programmazione strutturata. Questo paradigma impone l'uso esclusivo di tre strutture di base per la costruzione di ogni algoritmo. Queste tre strutture possono essere combinate tra loro, giustapponendole o nidificandole una dentro l'altra. Le tre strutture sono rappresentate in figura 3.
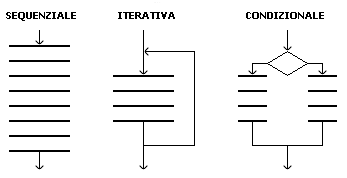 |
Ciň che č assolutamente 'proibito' dalle regole della programmazione strutturata č l'inserimento di salti ('go to') al di fuori delle strutture iterativa e condizionale; questi salti renderebbero particolarmente illeggibile e poco ordinata la struttura del programma, con pesanti conseguenze sulla sua efficienza e sulla possibilitŕ di apportarvi delle correzioni. In caso di programmi scritti con uno stile particolarmente disordinato si parla di 'spaghetti programming'.
Per poter essere eseguito da un elaboratore elettronico, ogni algoritmo deve essere codificato mediante le parole chiave di un linguaggio di programmazione. Un simile linguaggio č costituito da un insieme di parole e di regole sintattiche che ci consentono di tradurre in termini precisi e non ambigui i singoli passi che costituiscono un algoritmo. In un certo senso si puň anche pensare ad un linguaggio di programmazione, come ad un tramite tra la nostra lingua parlata (ricca di forme e sfumature che la rendono ambigua ed inadatta a comunicare con una macchina) ed il linguaggio dell'elaboratore elettronico, il cosiddetto linguaggio macchina (che al contrario della nostra lingua parlata č un linguaggio assai povero di espressioni, ma dotato di una precisione 'millimetrica').
Il calcolatore non č in grado di tradurre in operazioni da eseguire le istruzioni codificate mediante un linguaggio di programmazione. L'unico linguaggio con cui il computer č in grado di operare č il linguaggio macchina. Dobbiamo quindi dotarci di appositi programmi (scritti in linguaggio macchina!) che si occupino della traduzione delle istruzioni dei nostri programmi scritti con un linguaggio di programmazione, nel linguaggio della macchina.
Questo tipo di programmi traduttori sono classificabili in due categorie principali, in base al loro modo di operare la traduzione:
Il vantaggio dell'uso di un interprete rispetto ad un compilatore sta nel fatto che il programma sorgente puň essere modificato in ogni momento e poi inviato immediatamente in esecuzione, senza la necessitŕ di dover eseguire ulteriori passaggi. In generale perň, un programma compilato č molto piů efficiente di un programma interpretato. Il Perl, oggetto di queste dispense, č un linguaggio interpretato, ma garantisce una elevata efficienza grazie al fatto che integra delle macro istruzioni giŕ pronte per essere utilizzate. Uno dei piů famosi linguaggi di programmazione, il BASIC, č spesso un linguaggio interpretato. Viceversa il C, il Fortran ed il Pascal sono dei linguaggi dotati di un compilatore.
Abbiamo accennato nelle pagine precedenti al fatto che l'elaboratore elettronico č in grado di memorizzare i dati su cui opera in apposite celle di memoria. Queste celle possono essere utilizzate con un linguaggio di programmazione di alto livello, mediante l'uso delle variabili.
Le variabili sono delle strutture in cui č possibile memorizzare dei dati. L'uso delle variabili semplifica di molto l'accesso diretto alle locazioni di memoria. La memoria RAM di un computer č un insieme molto grande di bit, che possono assumere il valore di zero o uno (acceso o spento). Un gruppo di 8 bit costituisce un byte; gruppi di due, tre, quattro, otto byte costituiscono una parola, la cui lunghezza varia a seconda dell'architettura hardware della macchina (si parla in questo caso di macchine a 16, 24, 32 o 64 bit).
Per rappresentare in notazione binaria un numero intero compreso tra 0 e 255, sono necessari 8 bit (1 byte). Ogni carattere alfabetico e di punteggiatura puň essere codificato mediante un numero compreso tra 0 e 127, quindi per rappresentare un carattere alfanumerico nella memoria di un computer č sufficiente un byte. Per memorizzare una parola di 10 caratteri saranno necessari 10 byte.
Esistono diversi tipi di dato che possono essere memorizzati all'interno di un calcolatore elettronico, in particolare di solito distinguiamo i seguenti:
I puntatori sono un tipo di dato fondamentale in un linguaggio come il C. In pratica un puntatore č una struttura dati che permette di memorizzare l'indirizzo di memoria di un'altra variabile. In Perl non faremo uso di puntatori, visto che non si accede mai direttamente alle locazioni di memoria della macchina.
La maggior comoditŕ nell'uso delle variabili sta nel non doversi preoccupare (se non in casi particolari) della dimensione in bit del dato che intendiamo trattare e nel poter attribuire un identificativo mnemonico (nome della variabile) alle variabili stesse.
Cosě invece di dover lavorare a diretto contatto con le locazioni di memoria e i loro indirizzi, per memorizzare un numero o una parola ci basterŕ assegnarla ad una variabile: 'a=13', oppure 'b="casa"', 'nome="Marco"', 'x=$y+$z-17' e cosě via.
I linguaggi di programmazione tradizonali, come il Fortran, il Pascal o il BASIC, richiedono che sia definita a priori il tipo di ogni variabile: se la variabile 'a' č di tipo numerico intero, non potrŕ contenere null'altro che numeri interi; se la variabile 'b' č una variabile stringa, non potrŕ contenere altro che sequenze di caratteri alfanumerici. Inoltre le operazioni consentite sulle variabili dipenderanno dal tipo di variabili usate (ad esempio sarŕ possibile effettuare il prodotto tra due numeri, ma non tra due stringhe).
In Perl (ma giŕ in C č presente questo principio) i tipi di dato tendono a confondersi; in ogni caso l'interprete del linguaggio si regola di volta in volta in base al contesto. Ad esempio se imposteremo 'a=3', allora vorrŕ dire che la variabile a č intera, mentre impostando 'a="gatto"' comunicheremo automaticamente all'interprete che la variabile a in questo contesto č da considerarsi una stringa.
Un array č una struttura dati che ci permette di accedere ad un insieme di variabili identificate da uno stesso nome. Un array ha una lunghezza pari al numero di variabili di cui č costituito. Puň essere comodo pensare ad un array come ad una tabella costituita da una o piů righe e da piů colonne. Se l'array č formato da un'unica riga allora si parlerŕ di vettore, altrimenti parleremo di matrice.
Gli elementi dell'array (le variabili che lo costituiscono) sono identificate dallo stesso nome dell'array e da uno o piů indici, che indicano la posizione dell'elemento all'intero del vettore o della matrice.
Ad esempio, pensiamo di voler memorizzare i nomi dei giorni della settimana all'interno dell'array di tipo stringa chiamato giorno; avremo la seguente struttura:
$giorno[0] = "lunedi'" $giorno[1] = "martedi'" $giorno[2] = "mercoledi'" $giorno[3] = "giovedi'" $giorno[4] = "venerdi'" $giorno[5] = "sabato" $giorno[6] = "domenica" |
In Perl, come vedremo in seguito, gli indici degli elementi degli array cominciano dal numero 0; se l'array ha n elementi, allora l'indice dell'ultimo elemento sarŕ n-1.
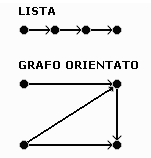
Una lista č una struttura simile a quella di un vettore; a differenza degli array, la lunghezza della lista puň variare in ogni momento aggiungendo o rimuovendo elementi; inoltre non č possibile raggiungere direttamente un preciso elemento della lista stessa, perché gli elementi non sono indicizzati come in un vettore: č necessario quindi scorrere la lista dal primo elemento, fino a quando non viene identificato l'elemento desiderato.
Un grafo č una generalizzazione di una lista: nelle liste ogni elemento ha un successore (escluso l'ultimo) ed un predecessore (escluso il primo); in un grafo invece la struttura puň essere molto piů 'intricata': un elemento puň avere piů successori e piů predecessori.
Fig. 4:
Esempio di lista e grafo
Quando si memorizza un dato su un supporto magnetico come un hard disk o un
nastro, o piů in generale su un'unitŕ di memoria di massa, lo si memorizza
utilizzando una struttura chiamata file. Un file č una sequenza di
byte; ai nostri fini un byte equivale ad un carattere. Il sistema non impone al
file nessun tipo di struttura e non assegna nessun significato al suo contenuto.
I byte assumono significato in funzione del programma che li interpreta .
Inoltre, come vedremo, tutto questo č vero non solo per i file su disco, ma
anche per le periferiche. I dischi, i messaggi di posta elettronica in partenza
ed in arrivo, i caratteri battuti sulla tastiera, l'output sul video del
terminale, i dati che passano da un programma all'altro attraverso i
pipe sono tutti visti dal sistema e dai programmi da esso gestiti come
file, ed in quanto tali non sono altro che sequenze di byte.
Per operare su di un file č necessario aprirlo associandogli un puntatore (handler) per successivi riferimenti. Al termine delle operazioni sul file, questo dovrŕ essere 'chiuso'; questa operazione implica la distruzione del puntatore al file stesso.